
LCM + Mapping Hidden Embedding = New Architecture Model


Recently I have been involved in training models from multimodal to text generation taking a look at the latest techniques to train the model
Scrolling from Twitter to Youtube I was shocked to see another major change in the world of AI.
This is because the open source multimodal next-generation infrastructure model “ Large Scale Conceptual Model (LCM) “ was announced at Meta’s
You may be familiar with the popular LLM (Large Language Model), such as ChatGPT. Their core mechanism is to predict the next word (token). But Meta has gone big this time. Their new model LCM (Large Concept Model) does not even look at the token, but directly understands the “meaning” of the sentence!
Say goodbye to “word by word” and welcome “overall grasp”
Imagine that when we understand a sentence, do we understand its meaning directly, rather than breaking it down into individual words first? LCM is like this. It no longer analyzes “word by word” like LLM, but encodes the entire sentence or paragraph into a high-dimensional vector, which Meta calls a “ concept “.
Simply put, LCM is a new type of AI that can create sentences and understand various things in a slightly different way than previous AI.
The “C” in LCM stands for “concept,” a model with a concept.
By the end of this video, you will understand what LCM is, the difference between traditional LLM and LCM, what makes LCM unique, how LCM works, and how to use LCM to create the architecture model
Before we start! 🦸🏻♀️
If you like this topic and you want to support me:
like my article; that will really help me out.👏
Follow me on my YouTube channel
Subscribe to me to get the latest article.
What is LCM?
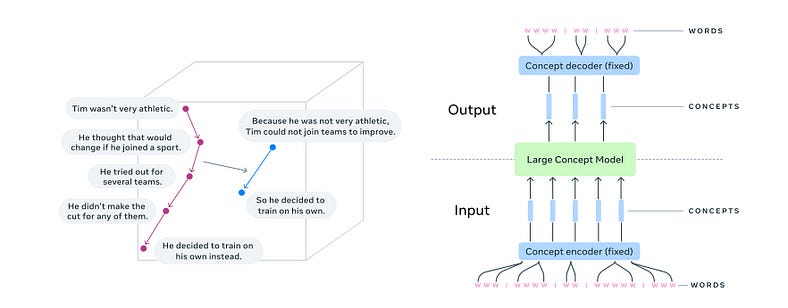
The large Concept Model is a new language model architecture proposed by Meta AI. It aims to imitate the way humans think, starting from macro concepts and then gradually filling in details. LCM treats each sentence as a concept and performs reasoning and generation at the sentence level instead of operating at the token level
In LCM, a concept usually corresponds to a complete sentence. it is a high-level semantic representation independent of the specific language and modality.
LLM Vs LCM
When looking at Traditional LLMs and LCMs, the way they handle understanding and memory is quite different.
Traditional LLM (such as GPT): Imagine you are reading a book, but your brain can only remember a few words at a time. To understand the following content, you have to review the previous words frequently. If the book is too long, your memory will be overloaded, resulting in biased understanding or missing information. This is the dilemma of LLM when dealing with long texts. Their “attention window” is limited and they cannot effectively remember and process too long contexts.
In contrast LCM (Large Concept Model): for example imagine that your brain can directly understand an entire sentence or paragraph as a complete “meaning unit”, just like giving each sentence or paragraph a label or a summary. When you read the book, you no longer need to remember every word but remember each “meaning unit”. In this way, even if the book is long, you only need to remember relatively few “meaning units”, the memory burden is greatly reduced, and the understanding will be more coherent and accurate.
What makes LCM unique
So why is LCM so unique? It‘s because it is similar to the process of human thought.
When we write, we first decide on an overall theme, like “What should I write about today?”, and then think about the specific content, right? LCM is similar in that it first grasps the big concept (theme) and then creates detailed sentences.
In addition, LCM has the following features:
Supports various languages: LCM can understand 200 languages using a special " SONAR " tool. Since sentences written in Spanish and English can be treated as “concepts” in the same way, you can create various AIs without worrying about language barriers.
Leave long sentences to us: LCM is good at creating long sentences. Ordinary AIs tend to make sentences sound strange or repeat the same thing over and over again when the sentence gets long. Still, LCM can create coherent sentences while considering the overall structure.
Zero-shot understanding of unknown languages: LCM can potentially understand languages that you have not trained on, as long as SONAR supports them, without any additional training.
How LCM Works
LCM’s architecture aims to treat language at a conceptual level, moving away from the token-based approach of traditional models. It consists of three main components:
Concept Encoder: This component converts words or phrases into abstract concepts, creating higher-level linguistic representations beyond surface-level text.
Large Concept Model: At the heart of the system, this component processes and understands concepts independently of specific sequences of words or tokens, focusing on the relationships and meaning behind the text.
Concept decoder: Translates abstract concepts back into human-readable language, ensuring the output is clear, coherent, and meaningful.
By dividing language processing into these different stages, LCM prioritizes the underlying meaning of a text over its surface structure. This results in output that is not only more accurate but also more consistent with the context and intent of the input.
Let’s start coding
While trying to understand the concept of coding the LCM approach, I came across Richard’s channel. I thank him for making the code open-source all the credit goes to him. Please note that I did not write a single line of the code; I am only here to explain it and give my feedback
Before we jump into the code I would like to show the base-LCM. the core is a standard decoder-only transformer surrounded by a PerNet and PostNet
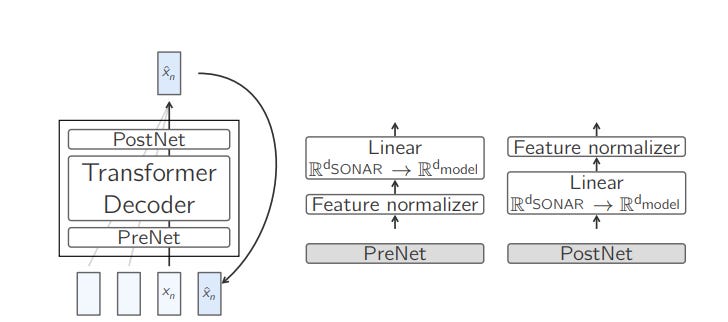
Basically, he creates a PreNet class to normalize the input embeddings before the main model processes them. It transforms the input SONAR embeddings into a format suitable for the model’s hidden dimensions. This normalization helps stabilize the training process and improve the model’s performance by appropriately scaling the input data.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Base-LCM Architecture Components
class PreNet(nn.Module):
"""
Maps input embeddings to the model's hidden dimension after normalization.
"""
def __init__(self, input_dim, hidden_dim):
super(PreNet, self).__init__()
self.linear = nn.Linear(input_dim, hidden_dim)
self.scaler_mean = 0.0 # Placeholder for robust scaler mean
self.scaler_std = 1.0 # Placeholder for robust scaler std
def normalize(self, x):
return (x - self.scaler_mean) / self.scaler_std
def forward(self, x):
x = self.normalize(x)
x = self.linear(x)
return xThen he creates PostNet to denormalise the output embeddings generated by the model. After the TransformerDecoder processes the normalized inputs, the PostNet converts the output back into a format that can be interpreted as SONAR embeddings this step is crucial for translating the model’s internal representations back into a usable form, such as subwords or sentences
class PostNet(nn.Module):
"""
Maps hidden state outputs back to the embedding space with denormalization.
"""
def __init__(self, hidden_dim, output_dim):
super(PostNet, self).__init__()
self.linear = nn.Linear(hidden_dim, output_dim)
self.scaler_mean = 0.0 # Placeholder for robust scaler mean
self.scaler_std = 1.0 # Placeholder for robust scaler std
def denormalize(self, x):
return x * self.scaler_std + self.scaler_mean
def forward(self, x):
x = self.linear(x)
x = self.denormalize(x)
return xhe set up TransformerDecoder to transduce a sequence of preceding concepts (or sentence embeddings) into a sequence of future concepts. It is a key component of the LCM, enabling it to generate coherent and contextually relevant outputs based on the input sequence. The Transformer architecture is known for its ability to handle long-range dependencies in data, making it suitable for generative tasks
class TransformerDecoder(nn.Module):
"""
Standard Decoder-Only Transformer.
"""
def __init__(self, hidden_dim, num_heads, num_layers, ff_dim, dropout=0.1):
super(TransformerDecoder, self).__init__()
self.layers = nn.ModuleList([
nn.TransformerDecoderLayer(
d_model=hidden_dim, nhead=num_heads, dim_feedforward=ff_dim, dropout=dropout
)
for _ in range(num_layers)
])
self.pos_encoder = nn.Parameter(torch.zeros(1, 512, hidden_dim)) # Positional encoding
def forward(self, x):
seq_len = x.size(1)
x = x + self.pos_encoder[:, :seq_len]
for layer in self.layers:
x = layer(x, x) # Self-attention in decoder layers
return x
Then he creates BaseLCM refers to the baseline architecture for the Large Concept Model, which incorporates the PreNet, PostNet, and TransformerDecoder. It is designed for the task of next-concept prediction, where the model predicts the next concept in a sequence based on the preceding concepts. the BaseLCM serves as the foundational model
class BaseLCM(nn.Module):
"""
Base Large Concept Model (LCM):
- PreNet: Maps input embeddings to hidden space.
- TransformerDecoder: Autoregressively processes embeddings.
- PostNet: Maps output back to the embedding space.
"""
def __init__(self, input_dim, hidden_dim, num_heads, num_layers, ff_dim, output_dim):
super(BaseLCM, self).__init__()
self.prenet = PreNet(input_dim, hidden_dim)
self.transformer_decoder = TransformerDecoder(hidden_dim, num_heads, num_layers, ff_dim)
self.postnet = PostNet(hidden_dim, output_dim)
def forward(self, x):
x = self.prenet(x)
x = self.transformer_decoder(x)
x = self.postnet(x)
return xFinally, he designed The BaseLCM function to operate entirely in the SONAR embedding space. Both the input and output are continuous numerical vectors with the same dimensionality (256).
This consistency ensures the model can seamlessly integrate with other components of a pipeline that uses SONAR embeddings. The test confirms that the model processes the inputs correctly, preserving the batch size and sequence structure while applying its transformations.
This architecture is designed for tasks where the input and output remain in a shared semantic embedding space, such as sentence encoding or intermediate processing
# Testing the Base-LCM architecture
def test_base_lcm():
batch_size = 4
sequence_length = 10
input_dim = 256 # SONAR embedding dimension (e.g., pre-encoded sentences)
hidden_dim = 512
num_heads = 8
num_layers = 6
ff_dim = 2048
output_dim = 256 # Output embedding dimension (same as input)
# Random input to simulate SONAR embeddings
input_embeddings = torch.randn(batch_size, sequence_length, input_dim)
# Initialize and test Base-LCM
model = BaseLCM(input_dim, hidden_dim, num_heads, num_layers, ff_dim, output_dim)
output_embeddings = model(input_embeddings)
print("Input shape:", input_embeddings.shape)
print("Output shape:", output_embeddings.shape)
if __name__ == "__main__":
test_base_lcm()Guys, he made more examples with different approaches. I don’t want to take all his code and explain it here. Instead, I encourage you to visit his channel and check it out. We’re here to help each other and spread useful content, so feel free to explore it. I’m just here to explain the concept of LCM, share my learning journey, and show you what I’ve found.
Check out the code : [link]
A bit of technical terminology
Finally, here is a summary of the terminology used in this article:
Large-scale conceptual model (LCM): AI that understands words as “concepts”
Concept: A high-level semantic unit that is language and modality-independent
SONAR: A tool used by LCM that can understand various languages
Base-LCM: A basic model that directly predicts the next “concept”
Diffusion-based LCM: A model for creating natural “concepts” by removing noise
Quantized LCM: A model for efficiently grouping and handling “concepts”
LPCM: A model that adds planning capabilities to LCM
Remembering these terms will help you understand LCM even better!
Conclusion:
Meta’s LCM paper has undoubtedly opened a new door for the field of NLP. It indicates that we are moving from “understanding words” to a higher level of “understanding meaning”.
Although it is still in the early stages of research, the potential of LCM is huge. It is expected to completely change the way we interact with machines and bring unlimited possibilities for the future development of artificial intelligence.
Let us wait and see how this “concept-driven” NLP revolution will reshape our world!
Reference :
🧙♂️ I am an AI Generative expert! If you want to collaborate on a project, drop an inquiry here or Book a 1-on-1 Consulting Call With Me.