


In this Story, I have a super quick tutorial showing you how to create a multi-agent chatbot using LangGraph, Reflection, and Gemini 2.5 to build a powerful full-stack agent chatbot for your business or personal use.
On June 3, 2025, Google released the official template “Gemini Fullstack LangGraph”, which combines the Gemini 2.5 series with LangChain/LangGraph as open source!
It is a full-stack solution that helps developers quickly build intelligent research tools.
The project is based on the Google Gemini 2.5 large model and the LangGraph framework, integrating the React front-end and the LangGraph back-end capabilities. Its integration enables dynamic search query generation, network information collection using the Google Search API, knowledge gap analysis, and comprehensive answer output with citations.
It has already gained over 10,000 stars on GitHub just a few days after its release, and is becoming a hot topic among LLM engineers.
It is very convenient, whether for local development or deployment through Docker, especially suitable for technical teams that want to implement intelligent research functions quickly.
Before we start! 🦸🏻♀️
If you like this topic and you want to support me:
Like my article, which will really help me out.👏
Follow me on my YouTube channel
Subscribe to me to get the latest articles.
Let me show you a quick demo of a live chatbot so you can see how it works behind the scenes.
When you ask a question, the AI agent doesn’t just jump straight into a web search. Instead, it takes a step back and uses the Gemini model to understand what you’re asking deeply.
It breaks your question down into its core parts, explores the context, and thinks about it from multiple angles, just like a skilled researcher planning their approach before diving into a topic.
Then comes the search phase. The AI sends those smart queries to the web using the Google Search API. But it doesn’t stop at collecting links. It reads through the content of those web pages, understands the information, and extracts the most important and relevant pieces — again, powered by the Gemini model.
Now comes the coolest part: reflection.
The AI pauses and asks itself:
“Do I have enough information to answer this well?”
“Are there any blind spots, gaps, or conflicting facts?”
If it notices anything missing or unclear, it doesn’t just move on. It goes back, generates more refined and focused search queries, and repeats the process — gathering, reading, and thinking again. This iterative loop helps it build a deeper, more accurate understanding of the topic. And don’t worry — it has smart controls in place so it doesn’t get stuck in an endless cycle.
Finally, once it’s confident it has enough quality information, the AI synthesizes everything into one clear, structured answer. It explains the topic in a way that’s easy to understand, and — most importantly — it includes source links so you can verify where the info came from.
So in the end, you’re not just getting a fast response — you’re getting a thoughtful, well-researched answer you can trust
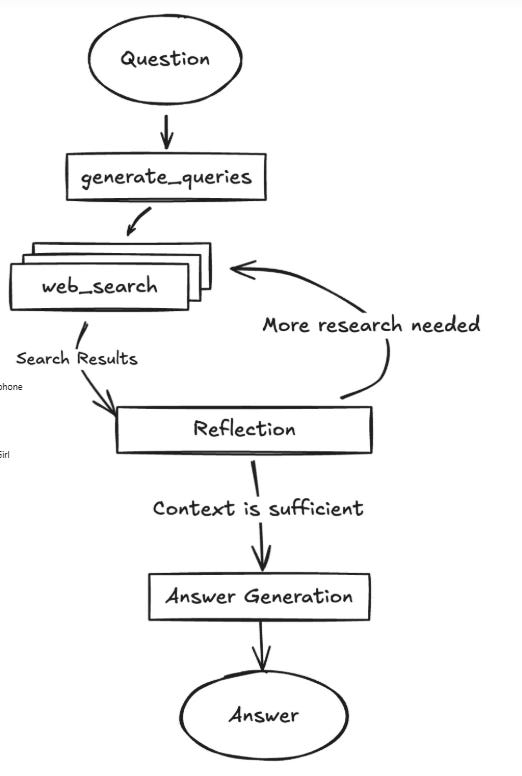
Features of Gemini Fullstack LangGraph
The biggest attraction of Gemini Fullstack LangGraph is that it comes standard with a “deep digging agent.”
Rather than a one-off prompt dialogue, if the answer lacks supporting evidence, the system will autonomously repeat additional searches and return highly reliable answers and source links.
This design concept has been described as an epitome of the “Deep Research Agent” being researched within Google, and its greatest appeal is that it can easily be adapted to serve as the basis for information-discovery SaaS.
The second feature is that multi-tool calls and conditional branching can be achieved simply by defining LangGraph nodes/edges in code, and it is also compatible with the LangGraphAgent class of the Vertex AI SDK, making it easy to migrate to the cloud in the future.
The third practical benefit is that it can be launched using a single Docker image, eliminating the need to separate the front and backend, which allows for quick deployment.
The UI does not block even when outputting long text because Redis Pub/Sub streams the tokens. This design that balances development efficiency and user experience is the true value of Gemini Fullstack LangGraph.
How it Works :
The core concept of this “full-stack intelligent agent” system is to make conversational AI no longer just generate answers, but to provide evidence-based insights through a transparent and traceable research process.
Phase 1: Query Generation
They create generate_query to generate search queries based on a user’s question using Gemini 2.0 Flash. It first extracts configuration settings from the config parameter and checks if an initial number of search queries is already set in the state; if not, it uses a default value from the configuration.
Then, it initialises the Gemini 2.0 Flash model using the specified model name, temperature, retry count, and API key. It structured the output format SearchQueryListto ensure the results follow a specific structure.
Next, it formats a prompt using the current date, the topic extracted from the user's messages, and the number of queries to generate.
def generate_query(state: OverallState, config: RunnableConfig) -> QueryGenerationState:
"""LangGraph node that generates a search queries based on the User's question.
Uses Gemini 2.0 Flash to create an optimized search query for web research based on
the User's question.
Args:
state: Current graph state containing the User's question
config: Configuration for the runnable, including LLM provider settings
Returns:
Dictionary with state update, including search_query key containing the generated query
"""
configurable = Configuration.from_runnable_config(config)
# check for custom initial search query count
if state.get("initial_search_query_count") is None:
state["initial_search_query_count"] = configurable.number_of_initial_queries
# init Gemini 2.0 Flash
llm = ChatGoogleGenerativeAI(
model=configurable.query_generator_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
structured_llm = llm.with_structured_output(SearchQueryList)
# Format the prompt
current_date = get_current_date()
formatted_prompt = query_writer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
number_queries=state["initial_search_query_count"],
)
# Generate the search queries
result = structured_llm.invoke(formatted_prompt)
return {"query_list": result.query}Phase 2: Parallel Web Research
The continue_to_web_research function is a LangGraph node that takes the list of generated search queries from the current state and creates a separate Send Instructions for each query.
It loops through the query_list using enumerate to assign each query a unique ID, and for each one, it returns a Send command targeting the "web_research" node, passing both the search_query text and its corresponding id as a dictionary.
def continue_to_web_research(state: QueryGenerationState):
"""LangGraph node that sends the search queries to the web research node.
This is used to spawn n number of web research nodes, one for each search query.
"""
return [
Send("web_research", {"search_query": search_query, "id": int(idx)})
for idx, search_query in enumerate(state["query_list"])
]Phase 3: Intelligent Web Research
After that, they create web_research performs a web search using the native Google Search API along with Gemini 2.0 Flash to gather information based on a given search query.
It first extracts configuration settings from the config, then formats a search prompt using the current date and the search query. It uses the genai_client to send this prompt to the Gemini model, enabling the use of Google Search tools with zero temperature for consistent output.
After receiving the response, it resolves the resulting URLs to shorter versions to save tokens and processing time, then extracts citation data and inserts citation markers into the response text.
def web_research(state: WebSearchState, config: RunnableConfig) -> OverallState:
"""LangGraph node that performs web research using the native Google Search API tool.
Executes a web search using the native Google Search API tool in combination with Gemini 2.0 Flash.
Args:
state: Current graph state containing the search query and research loop count
config: Configuration for the runnable, including search API settings
Returns:
Dictionary with state update, including sources_gathered, research_loop_count, and web_research_results
"""
# Configure
configurable = Configuration.from_runnable_config(config)
formatted_prompt = web_searcher_instructions.format(
current_date=get_current_date(),
research_topic=state["search_query"],
)
# Uses the google genai client as the langchain client doesn't return grounding metadata
response = genai_client.models.generate_content(
model=configurable.query_generator_model,
contents=formatted_prompt,
config={
"tools": [{"google_search": {}}],
"temperature": 0,
},
_ )
# resolve the urls to short urls for saving tokens and time
resolved_urls = resolve_urls(
response.candidates[0].grounding_metadata.grounding_chunks, state["id"]
)
# Gets the citations and adds them to the generated text
citations = get_citations(response, resolved_urls)
modified_text = insert_citation_markers(response.text, citations)
sources_gathered = [item for citation in citations for item in citation["segments"]]
return {
"sources_gathered": sources_gathered,
"search_query": [state["search_query"]],
"web_research_result": [modified_text],
}Phase 4: Gap Detection
The important function is reflection to analyse the current web research results and identify any remaining knowledge gaps, generating follow-up queries if needed. It starts by updating the research_loop_count and selecting a reasoning model—either from the state or from the configuration.
Then, it formats a prompt with the current date, the research topic and a combined summary of all prior web research results. Using this prompt, it invokes Gemini ChatGoogleGenerativeAI With a structured output expected in a Reflection format.
The model analyses the information and returns a structured response containing whether the information is sufficient (is_sufficient), a description of the knowledge gap, and any suggested follow_up_queries.
Finally, the function returns an updated state dictionary including these results, along with the incremented loop count and the number of queries that have already been run.
def reflection(state: OverallState, config: RunnableConfig) -> ReflectionState:
"""LangGraph node that identifies knowledge gaps and generates potential follow-up queries.
Analyzes the current summary to identify areas for further research and generates
potential follow-up queries. Uses structured output to extract
the follow-up query in JSON format.
Args:
state: Current graph state containing the running summary and research topic
config: Configuration for the runnable, including LLM provider settings
Returns:
Dictionary with state update, including search_query key containing the generated follow-up query
"""
configurable = Configuration.from_runnable_config(config)
# Increment the research loop count and get the reasoning model
state["research_loop_count"] = state.get("research_loop_count", 0) + 1
reasoning_model = state.get("reasoning_model") or configurable.reasoning_model
# Format the prompt
current_date = get_current_date()
formatted_prompt = reflection_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n\n---\n\n".join(state["web_research_result"]),
)
# init Reasoning Model
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.with_structured_output(Reflection).invoke(formatted_prompt)
return {
"is_sufficient": result.is_sufficient,
"knowledge_gap": result.knowledge_gap,
"follow_up_queries": result.follow_up_queries,
"research_loop_count": state["research_loop_count"],
"number_of_ran_queries": len(state["search_query"]),
}Phase 6: Iterative control (up to 5 rounds)
Next, they create evaluate_research to route a node that decides whether to continue web research or move to the final answer based on how many research loops have run and whether the gathered information is sufficient.
It first loads configuration settings and determines the maximum allowed number of research loops, either from the state or from the config. Then, it checks if the current results are marked as sufficient (is_sufficient) or if the research_loop_count has reached or exceeded the maximum.
If either condition is true, it returns "finalize_answer" to end the loop. Otherwise, it creates a list of Send instructions—one for each follow_up_query—and sends them to the "web_research" node with updated IDs, continuing the research process.
def evaluate_research(
state: ReflectionState,
config: RunnableConfig,
) -> OverallState:
"""LangGraph routing function that determines the next step in the research flow.
Controls the research loop by deciding whether to continue gathering information
or to finalize the summary based on the configured maximum number of research loops.
Args:
state: Current graph state containing the research loop count
config: Configuration for the runnable, including max_research_loops setting
Returns:
String literal indicating the next node to visit ("web_research" or "finalize_summary")
"""
configurable = Configuration.from_runnable_config(config)
max_research_loops = (
state.get("max_research_loops")
if state.get("max_research_loops") is not None
else configurable.max_research_loops
)
if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:
return "finalize_answer"
else:
return [
Send(
"web_research",
{
"search_query": follow_up_query,
"id": state["number_of_ran_queries"] + int(idx),
},
)
for idx, follow_up_query in enumerate(state["follow_up_queries"])
]Phase 7: Answer Synthesis
Finally, they create a finalize_answer function to prepare the final research output by generating a clean, well-cited summary. It begins by loading configuration settings and selecting the reasoning model.
Then, it formats a prompt using the current date, the research topic and the compiled web research summaries. It sends this prompt to the Gemini model to generate a final research report.
After receiving the result, it replaces all short URLs in the generated content with their corresponding original URLs by checking against the sources_gathered list, ensuring proper citations. It also filters and keeps only the sources that were cited in the final content.
Finally, it returns an updated state with the completed summary in the form of an AIMessage and the list of used sources undermessages sources_gathered, respectively.
def finalize_answer(state: OverallState, config: RunnableConfig):
"""LangGraph node that finalizes the research summary.
Prepares the final output by deduplicating and formatting sources, then
combining them with the running summary to create a well-structured
research report with proper citations.
Args:
state: Current graph state containing the running summary and sources gathered
Returns:
Dictionary with state update, including running_summary key containing the formatted final summary with sources
"""
configurable = Configuration.from_runnable_config(config)
reasoning_model = state.get("reasoning_model") or configurable.reasoning_model
# Format the prompt
current_date = get_current_date()
formatted_prompt = answer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n---\n\n".join(state["web_research_result"]),
)
# init Reasoning Model, default to Gemini 2.5 Flash
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.invoke(formatted_prompt)
# Replace the short urls with the original urls and add all used urls to the sources_gathered
unique_sources = []
for source in state["sources_gathered"]:
if source["short_url"] in result.content:
result.content = result.content.replace(
source["short_url"], source["value"]
)
unique_sources.append(source)
return {
"messages": [AIMessage(content=result.content)],
"sources_gathered": unique_sources,
}How to use Gemini Fullstack LangGraph
From here, we will introduce a typical way to use Gemini Fullstack LangGraph.
Run the command below, and if the cloning is completed as shown in the image, it is OK.
git clone https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart.gitNow, create a virtual environment as described in the Usage section and move to the cloned directory.
cd backend
copy .env.example .envEnter your Gemini API key in the .env file and save it.
GEMINI_API_KEY=AIzaSyDacnBc6tUk5FKHX65EB6whwj_L1hvH11kAfter installing the dependent libraries and running the make dev command, the execution result will be displayed
# for backend
cd backend
pip install .
# for frentend
cd frontend
npm install
4. Then start the backend:
langgraph devOpen another terminal and run
make devAccess http://localhost:5173/app/ from your browser, and Gemini Fullstack LangGraph will start up as shown in the image below.
For now, the prompt can be anything, so let’s check the behaviour
The problem I faced :
Please, if you are a Windows user, use this code in your file vite.config.ts
import path from "node:path";
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react-swc";
import tailwindcss from "@tailwindcss/vite";
export default defineConfig({
plugins: [react(), tailwindcss()],
base: "/app/",
resolve: {
alias: {
"@": path.resolve(__dirname, "./src"),
},
},
server: {
proxy: {
"/api": {
target: "http://127.0.0.1:2024",
changeOrigin: true,
},
},
},
});Conclusion :
The value of this project goes beyond just offering a working code example — it highlights key trends in modern AI development. It showcases a combinatorial AI architecture, where multiple AI components work together to form a more capable system rather than relying on a single large model.
Its explainable design, made possible by LangGraph’s visualisation tools, brings transparency to the AI’s decision-making process.
The project also models iterative information processing, mimicking how humans refine their understanding through repeated cycles of research. And by integrating real-time web search, the AI can access the latest information, moving beyond the limitations of static training data.
Reference :
🧙♂️ I am an AI Generative expert! If you want to collaborate on a project, drop an inquiry here or book a 1-on-1 Consulting Call With Me.
A sharp and well-structured read. As multi-agent frameworks mature, integrating spatial context into voice systems could be the key to more intuitive, real-world interactions.